Large Language Models didn’t emerge from a single “eureka moment.” They are the result of stacked breakthroughs — architectural, algorithmic, and operational — layered over the last few years.
From “Attention is all you need” to reinforcement learning from human feedback, mixture-of-experts, retrieval-augmented generation, and multimodal reasoning, each step removed a hard constraint that previously limited what language models could do.
This post walks through the key breakthroughs, why they mattered, and how they fit together, with a timeline to show how modern LLMs evolved into the systems we use today.
A high-level timeline
2017 – Transformers replace RNNs
2019–2020 – Scaling laws + GPT-style pretraining
2021 – Emergent abilities, few-shot learning
2022 – RLHF & instruction-tuned assistants
2022–2023 – Mixture of Experts, retrieval, chain-of-thought
2023–2024 – Efficient fine-tuning, open models, multimodality
Let’s break this down.
1. “Attention Is All You Need” — the architectural reset (2017)
Before Transformers, language models relied on recurrent neural networks (RNNs) and LSTMs. These models processed text sequentially, making training slow and limiting how much context they could realistically use.
The Transformer architecture introduced a radical simplification:
- No recurrence
- No convolutions
- Just self-attention + feed-forward layers
Self-attention allowed each token to directly “look at” every other token in a sequence, enabling:
- Long-range dependency modeling
- Massive parallelization on GPUs
- Cleaner scaling to large datasets
This single architectural decision is the foundation of every modern LLM.
Why it mattered
- Training speed increased by orders of magnitude
- Context windows became flexible
- Model design became modular and extensible
Without Transformers, none of the later breakthroughs would have been feasible.
2. Scaling laws — when “bigger” became predictable (2019–2020)
Once Transformers proved effective, researchers began asking a pragmatic question:
If we scale models and data, what happens — and can we predict it?
Empirical scaling laws showed that:
-
Performance improves smoothly as a power-law with respect to
- Model size
- Dataset size
- Compute budget
This meant progress was no longer guesswork. Teams could plan investments in compute and data with reasonable confidence.
GPT-3 demonstrated the implications:
- One model
- Trained on massive unlabeled text
- Capable of translation, QA, summarization, and reasoning — without task-specific training
This was also the moment few-shot learning became mainstream.
Why it mattered
- Shifted AI from task-specific models to generalist models
- Created the foundation for prompt-based interfaces
- Justified large-scale infrastructure investments
3. Emergent abilities & in-context learning (2020–2021)
As models grew, researchers observed something unexpected:
Certain abilities only appeared after models crossed specific size thresholds.
These included:
- Multi-step reasoning
- Code generation
- Logical inference
- Complex pattern completion
At the same time, in-context learning emerged:
- Models could learn new tasks from examples inside the prompt
- No gradient updates required
This reframed prompts as temporary programs rather than mere inputs.
Why it mattered
- Prompting became a new discipline
- LLMs started behaving less like text predictors and more like reasoning engines
4. Instruction tuning & RLHF — making models usable (2022)
Raw pretrained models were powerful — but unreliable. They:
- Ignored instructions
- Produced unsafe or irrelevant outputs
- Optimized likelihood, not helpfulness
Two techniques changed that:
Instruction tuning
Models were fine-tuned on datasets of:
- Human-written instructions
- Desired responses
This alone dramatically improved usability.
Reinforcement Learning from Human Feedback (RLHF)
RLHF added a second optimization loop:
- Humans rank model outputs
- A reward model learns human preferences
- The base model is optimized to maximize this reward
This transformed LLMs into assistants rather than autocomplete engines.
Why it mattered
- Enabled ChatGPT-style interfaces
- Improved safety and alignment
- Made smaller models outperform larger but unaligned ones
5. Mixture of Experts (MoE) — scaling without exploding costs (2022–2023)
Dense models scale linearly in compute — which gets expensive fast.
Mixture-of-Experts models introduced conditional computation:
- The model contains many expert sub-networks
- Only a small subset is activated per token
This allowed:
- Trillion-parameter models
- With compute costs closer to much smaller models
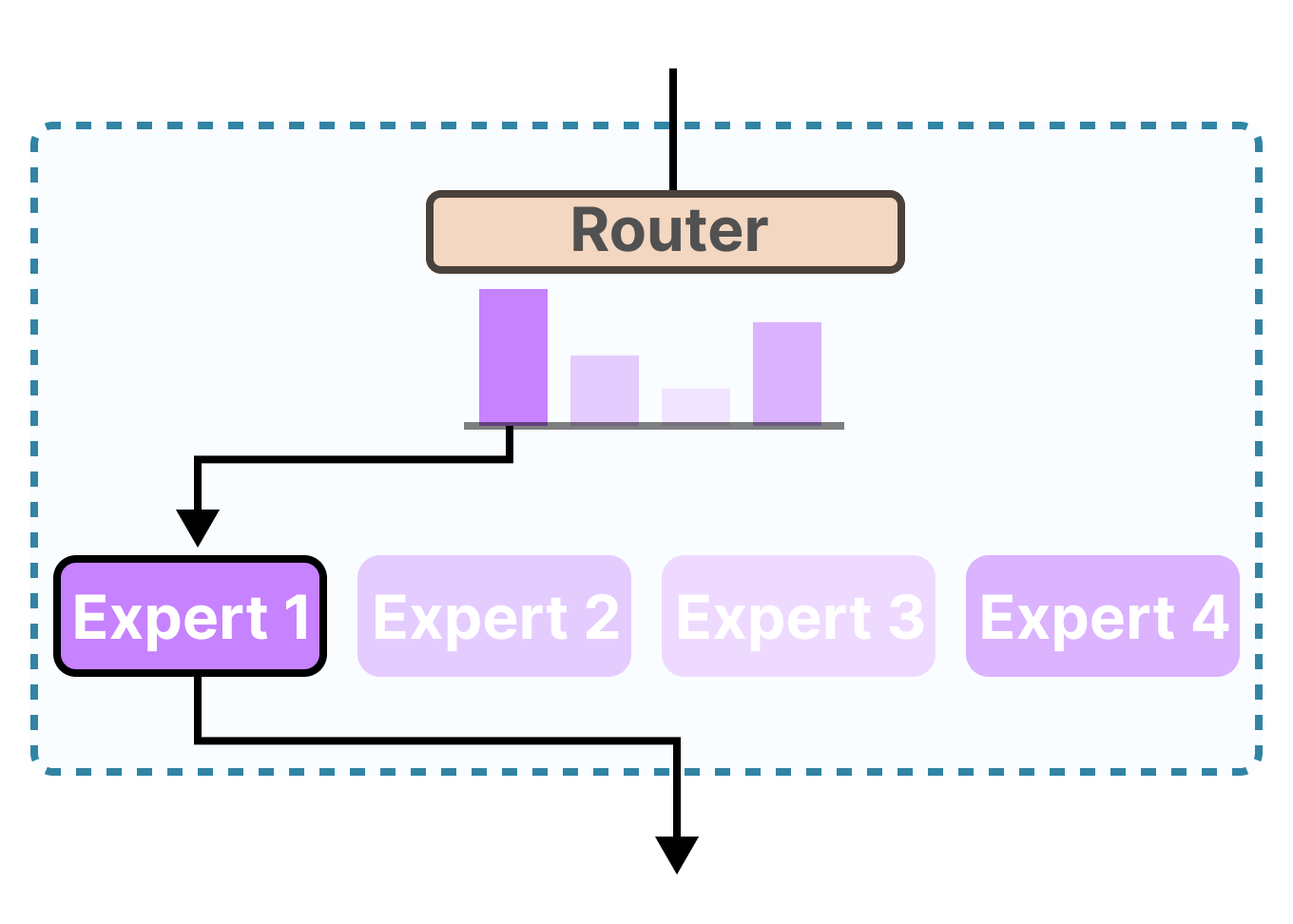
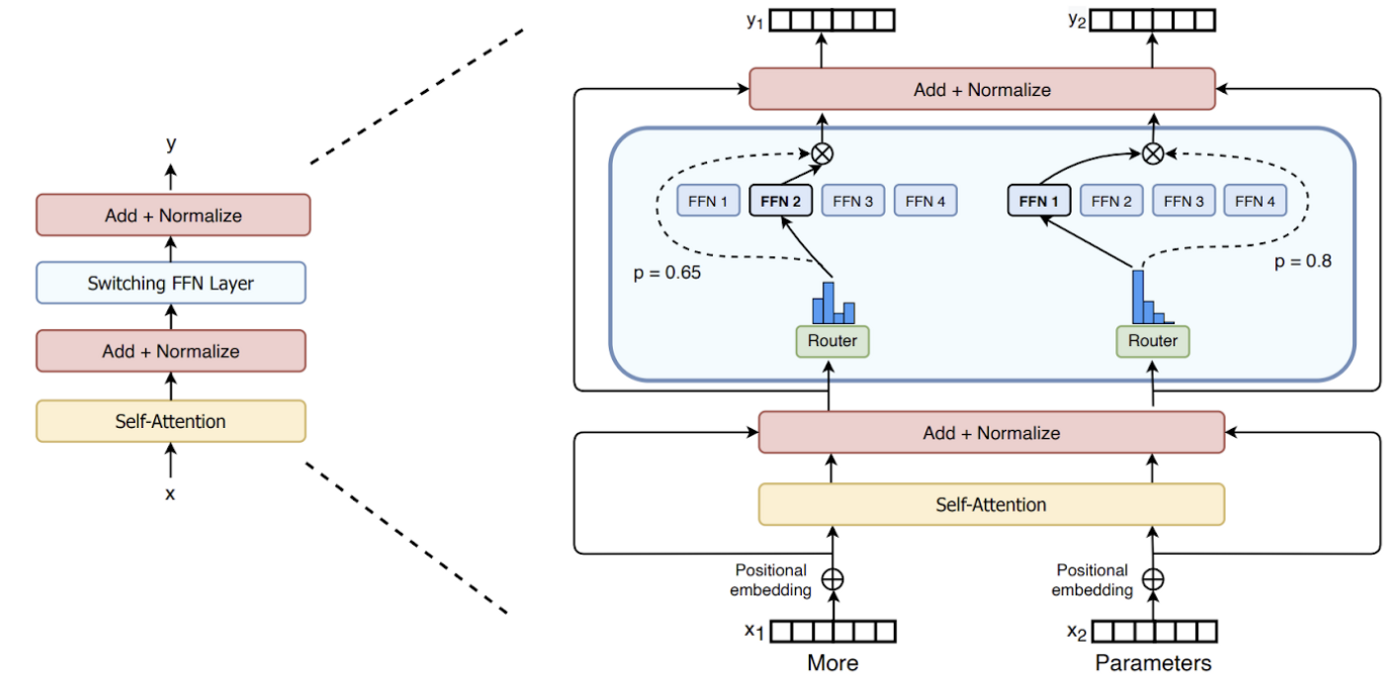
Why it mattered
- Massive capacity without proportional inference cost
- New efficiency frontier for foundation models
- Introduced new engineering challenges (routing, load balancing)
6. Retrieval-Augmented Generation — giving LLMs external memory
LLMs don’t know facts — they approximate them from training data. This leads to:
- Hallucinations
- Stale knowledge
- Overconfidence
Retrieval-Augmented Generation (RAG) changed the paradigm:
- Retrieve relevant documents at inference time
- Feed them into the model as context
- Generate grounded responses

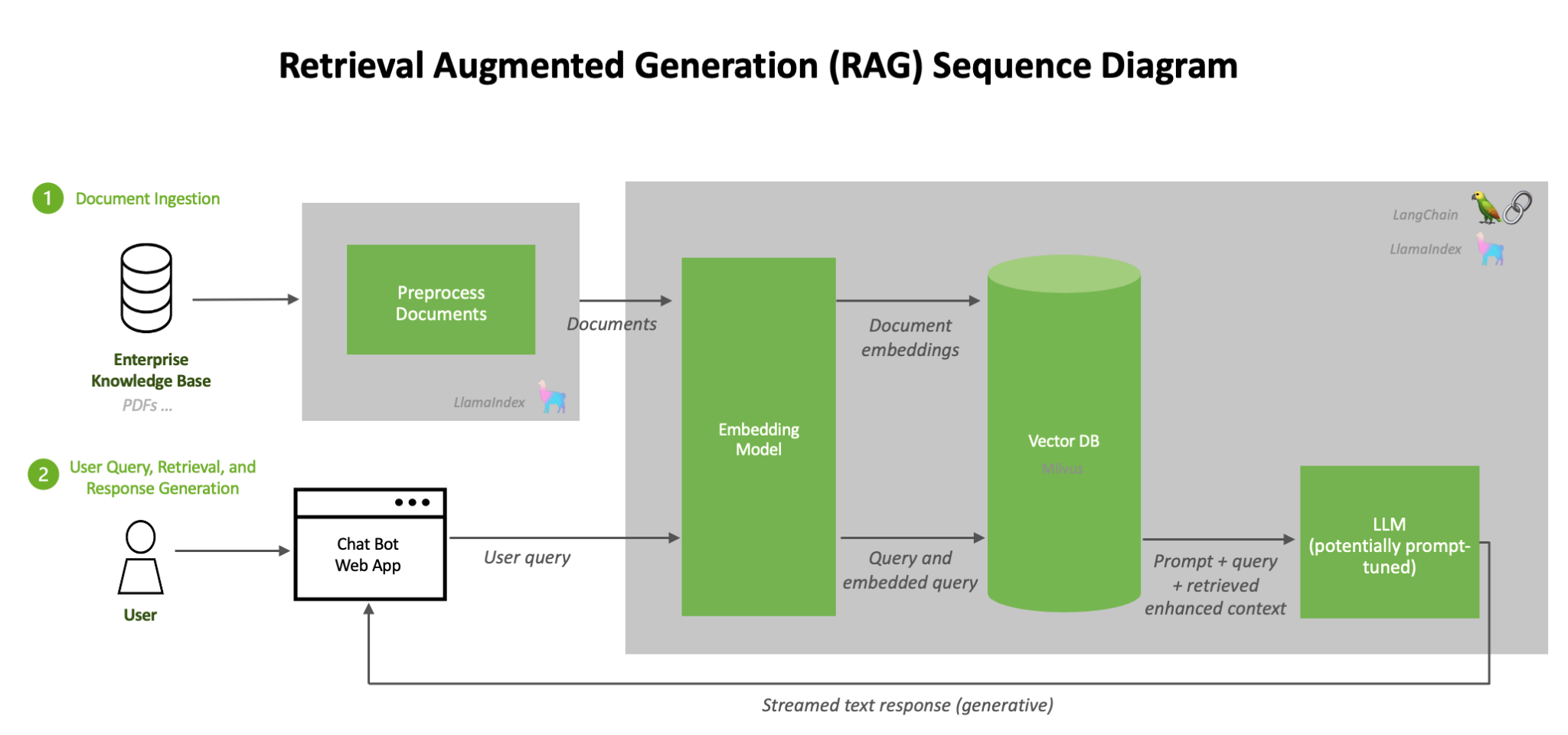
Why it mattered
- Improved factual accuracy
- Enabled enterprise and search use-cases
- Reduced need for constant retraining
7. Chain-of-Thought & reasoning-aware prompting
Researchers discovered that showing reasoning steps in prompts dramatically improved performance on:
- Math
- Logic
- Multi-step planning
This led to:
- Chain-of-Thought prompting
- Self-consistency sampling
- Tool-augmented reasoning
LLMs weren’t just predicting answers — they were learning to reason out loud.
Why it mattered
- Improved reliability on complex tasks
- Enabled agent-like behavior
- Bridged the gap between language and reasoning
8. Parameter-efficient fine-tuning & quantization (2023)
As models grew, full fine-tuning became impractical.
Solutions emerged:
- LoRA / adapters — train tiny low-rank matrices
- QLoRA — fine-tune 4-bit quantized models
This made it possible to:
- Fine-tune 30B–70B models on a single GPU
- Democratize model adaptation
Why it mattered
- Lowered cost barriers
- Enabled domain-specific assistants
- Accelerated open-source innovation
9. Open models & ecosystem acceleration
The release of models like LLaMA triggered a wave of:
- Community fine-tuning
- Instruction-aligned open assistants
- Rapid experimentation
Open weights + efficient tuning changed the innovation curve from centralized to distributed.
Why it mattered
- Faster research iteration
- Greater transparency
- More diverse applications
10. Multimodal LLMs — beyond text
Modern LLMs now:
- Read images
- Understand diagrams
- Process audio and video
A single transformer backbone can reason across modalities.
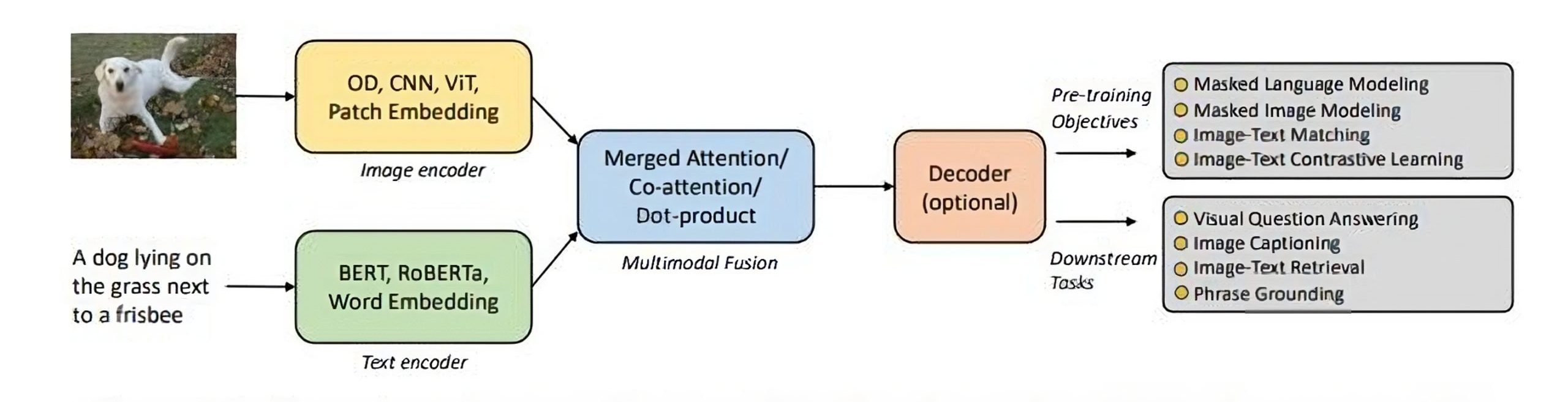
Why it mattered
- Enabled document understanding, design review, code + UI analysis
- Pushed LLMs toward general intelligence rather than text-only systems
What ties all of this together
LLMs are no longer:
- Just models
- Just architectures
They are systems combining:
- Pretraining
- Alignment
- Retrieval
- Reasoning
- Tool use
- Efficient deployment
Each breakthrough removed one bottleneck — and together they created a compounding effect.
What’s next
Looking forward, the next breakthroughs are likely to focus on:
- Long-term memory & agents
- More reliable reasoning
- Better alignment without constant human feedback
- Lower-cost inference at scale
- Regulation-aware deployment
The story of LLMs isn’t finished — but the last few years have already rewritten what we expect machines to do with language.
license: "Creative Commons Attribution-ShareAlike 4.0 International"